
The Audio-Visual Gap in Embodied AI
Vision models and audio models have both improved rapidly, but multimodal LLMs still struggle with first-person video that requires understanding both. I think this is a major bottleneck in egocentric AI, and it’s a data problem more than an architecture problem.
First-Person Video is an Audio Problem
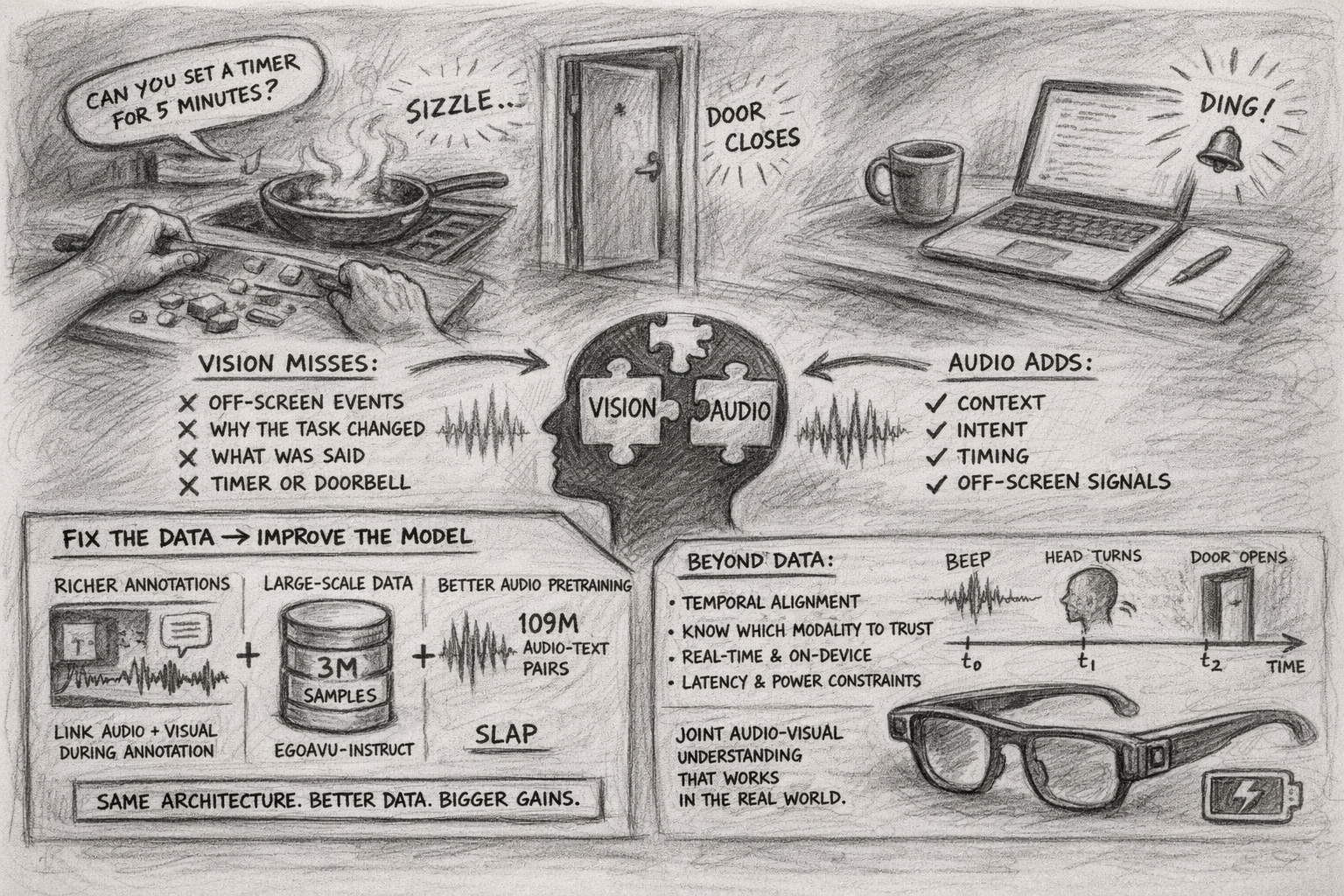
Third-person video is forgiving: stable camera, framed scene, subject in view. First-person video breaks those assumptions. The camera moves constantly, hands occlude the scene, and the person whose actions matter most is never visible. A knife hitting a cutting board when the hands are out of frame, a door closing off-screen, a conversation that explains why the person just changed tasks: in egocentric video, audio routinely carries context that vision misses.
Most multimodal LLMs bias heavily toward visual signals in egocentric settings because that’s what the training data rewards. Existing egocentric datasets lack text labels that coherently capture both modalities together. Narrations describe what’s visible, not what’s audible. So models learn to neglect audio cues. A vision-only model can identify objects on a counter but can’t tell that the pan is sizzling. It misses the verbal instruction that triggered a task switch. It has no way to detect an off-screen doorbell or timer.
Fix the Data, Fix the Model
EgoAVU builds a data generation pipeline that links audio and visual context during annotation. Cross-modal correlation modeling enriches narrations with joint audio-visual information, so the training signal has both modalities entangled from the start rather than fused at inference.
The resulting dataset, EgoAVU-Instruct, has 3 million samples. Fine-tuning multimodal LLMs on it yields up to 113% improvement on the EgoAVU benchmark and transfers to other egocentric benchmarks: up to 28% relative improvement on EgoTempo and EgoIllusion without being trained on them. The architectures didn’t change; the data did.
SLAP shows the same pattern on the audio side. It scales language-audio pretraining to 109 million audio-text pairs, up from a few million in prior CLAP-style models, while supporting variable-duration audio and combining contrastive, self-supervised, and captioning objectives in a single stage. State-of-the-art on audio-text retrieval and zero-shot classification.
Beyond Data: Temporal Alignment, Modality Trust, and On-Device Cost
EgoAVU and SLAP each solve part of the problem: better audio-visual data, better audio representations. But data is only the first bottleneck.
Audio and visual events don’t always coincide: a microwave beep precedes the door opening by several seconds, a notification sound triggers a head turn a moment later. Models need to learn these causal and temporal relationships, not just co-occurrence within the same clip. And even when events are aligned, which modality to trust depends on context. In a noisy kitchen, audio may be unreliable for identifying specific actions, but in a quiet office, a keyboard click is more informative than a static frame of someone at a desk. Current fusion approaches are mostly context-blind.
These problems get harder on-device. Egocentric applications like AR glasses are latency-sensitive and power-constrained. Processing both audio and video streams in real time is a systems challenge on top of the modeling one, and the fusion layer can’t be an expensive addition on top of already-heavy encoders.
The vision-language and audio-language stacks are each maturing independently. Joint audio-visual understanding that works on real hardware at real-time latency is the harder, less explored problem.