
Diffusion Models Learn to Think
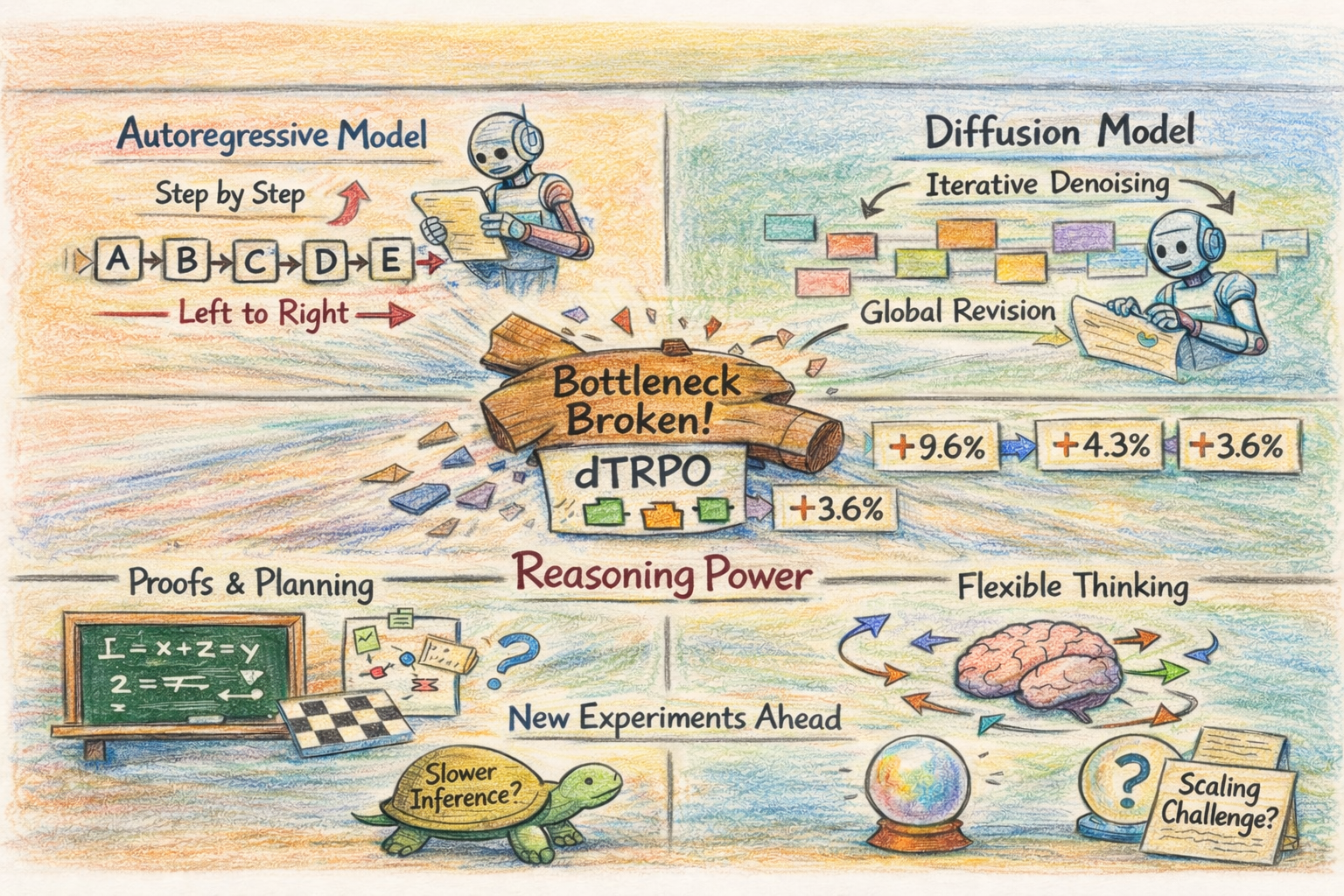
Every major reasoning system right now is autoregressive. DeepSeek-R1, OpenAI’s o-series, Qwen, Gemini. Tokens go left to right, RL goes on top. It’s easy to look at this and conclude that autoregressive generation is better suited to reasoning. I think we’ve been confusing a training limitation for an architectural one.
Diffusion language models generate text by iteratively denoising a masked sequence, refining all positions in parallel rather than committing to one token at a time. They haven’t been competitive on reasoning, but the bottleneck was cost, not capability. Applying RL to diffusion models required tracking every intermediate denoising step to compute trajectory probabilities, so training cost scaled linearly with the number of steps. Autoregressive models, with cheap probability computation, pulled ahead through RL post-training that diffusion models couldn’t match at scale despite earlier attempts.
The Training Bottleneck is Gone
dTRPO removes this bottleneck. Under KL regularization toward the base model (which you want anyway to prevent policy collapse), the probability ratio of newly unmasked tokens at any step is an unbiased estimator of the full intermediate-state ratio. The entire multi-step trajectory collapses to a single forward pass through a re-masked version of the final output. Training cost drops to roughly matching supervised fine-tuning, and the method is offline: generate trajectories once, train on them repeatedly. On a 7B diffusion LLM, dTRPO gets +9.6% on GPQA, +3.6% on GSM8K, +4.3% on HumanEval+, and +3.0% on IFEval over prior diffusion RL baselines. For the first time, we can compare autoregressive and diffusion architectures on reasoning with both having access to RL training at reasonable cost.
Why Diffusion Might Be Better for Reasoning
Autoregressive generation commits to tokens in order and can’t revise earlier decisions without re-generating from scratch. Chain-of-thought works around this: the model “thinks” by writing reasoning as text, then conditions on what it wrote. If step three of a ten-step proof goes wrong, the model either pushes through the error or starts over.
Diffusion models can revise any position at any step. For tasks that need global coherence, where early decisions constrain later ones, like proofs, planning, and code, I think the ability to revise globally rather than commit sequentially is a better fit for reasoning. Writing a proof often means realizing midway that the initial setup was wrong and restructuring the whole argument. An autoregressive model can’t do that without starting over. A diffusion model, in principle, can refine the early steps while working on later ones. Whether this advantage translates to practice is unproven; we don’t yet have evidence that diffusion models reason in qualitatively different ways. dTRPO makes the experiment possible, it doesn’t tell us the answer.
What Stands in the Way
Inference is slower: multiple denoising passes versus one-shot autoregressive decoding with KV caching. For reasoning tasks where you’re spending compute on thinking anyway, the overhead may be acceptable, but for interactive use it’s a real cost. Scaling laws for diffusion LLMs are far less mapped out than for autoregressive models, so it’s unclear whether the architectural advantages hold at larger scale. And dTRPO’s theory depends on KL regularization; how that interacts with aggressive policy updates is untested.
Architecture has been a settled question for most of the LLM era. Transformer, autoregressive, next token. The progress came from training recipes and post-training. Whether that stays true depends on what happens when diffusion models get the same RL treatment at scale. Does global revision give them an edge on problems that sequential decoding handles poorly: long proofs, complex planning, code with deep dependency chains? We can now run that experiment.