
Efficient Video Intelligence in 2026
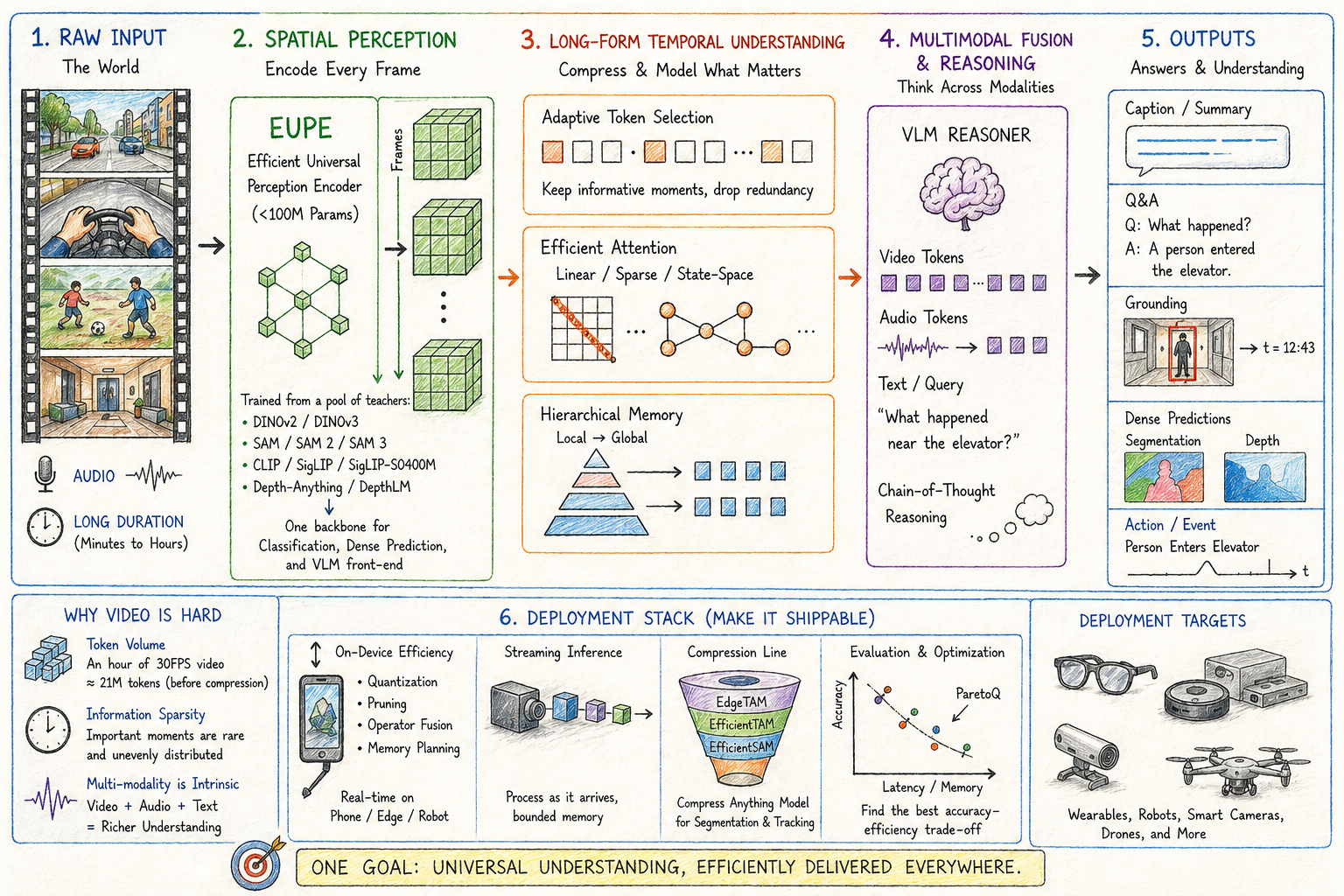
Five years ago, video understanding mostly meant action recognition on Kinetics-400 or short-clip captioning on MSR-VTT. Today, vision-language models reason about hour-long footage, on-device tracking segments any object at 16 FPS on a phone, and a single 100M-parameter encoder can match domain experts across image understanding, dense prediction, and VLM tasks. The shift came from rethinking what a video model needs to do, and from taking deployment constraints seriously.
This post walks through where efficient video intelligence stands in April 2026, following how a video system processes its input from raw frames through spatial perception, long-form temporal understanding, multimodal fusion and reasoning, and the deployment stack that makes any of it shippable.
A note up front: the post leans heavily on research from my own group, including EUPE, the EfficientSAM / Efficient Track Anything / EdgeTAM compression line, LongVU, Tempo, EgoAVU, VideoAuto-R1, DepthLM, and ParetoQ. I have tried to place each piece against the parallel and competing work in its section, but this is a perspective from inside one research program rather than a neutral survey.
Why Video Is Harder Than Text or Images
Token volume. A single minute of 30 FPS video at 224x224 resolution and ViT-B/16 patches produces 1,800 frames times 196 patches per frame, or 352K visual tokens before any text or audio, and an hour is 21M tokens before compression. No frontier LLM context window absorbs this naively, so every video model has to compress somewhere.
Information sparsity. Adjacent frames are usually nearly identical, and the interesting events are rare and unevenly distributed. A surveillance camera at 1 FPS over 24 hours produces 86,400 frames, and the question of interest may depend on three of them. Sampling every frame is wasteful, but uniform sampling drops the frames that matter, so adaptive selection is required.
Multi-modality is intrinsic. Video without audio is half a signal in egocentric, conversational, and many healthcare contexts, even though much surveillance footage is silent and sports broadcast audio is mostly commentary. Video with audio doubles the embedding cost and adds synchronization requirements, and training a native multimodal model is a different problem than bolting an audio adapter onto a vision encoder.
Vision Encoders: From Specialists to Universals
The first thing a video model does is encode each frame. Until recently, that meant picking an encoder family and accepting its weaknesses. Image-text contrastive models (CLIP, SigLIP, SigLIP 2) are the default VLM front-end for semantic retrieval but weak on dense prediction. Self-supervised ViTs (DINOv2, DINOv3) excel on dense prediction (segmentation, depth, correspondence) because their training objective preserves fine-grained spatial structure, but their features are not aligned to language. Segmentation foundation models (SAM, SAM 2 and the compressed variants below) are specialists for object proposals and tracking. Dense-prediction specialists (DepthAnything, MiDaS, DepthPro, DepthLM) handle depth.
A production video system on a wearable, robot, or smart camera cannot ship a separate backbone for each of these capabilities, and neither compromising on capability nor paying the memory-and-latency penalty is acceptable.
Agglomerative encoders and EUPE
The agglomerative-encoder thread addresses this directly. AM-RADIO (Ranzinger et al., Nvidia, CVPR 2024) introduced multi-teacher distillation for compact universal vision encoders, distilling CLIP, DINOv2, and SAM into a unified student. Theia (Shang et al., The AI Institute, CoRL 2024) targeted embodied-agent perception by distilling from CLIP, DINOv2, ViT, SAM, and Depth-Anything for robot learning. DUNE (Sariyildiz et al., Naver Labs Europe, CVPR 2025) extended this further with heterogeneous 2D and 3D teachers (DINOv2, MASt3R, Multi-HMR). The shared insight: vision foundation models trained for different objectives produce complementary feature spaces, and a small student can inherit the union if the distillation is set up well.
Our recent work on the Efficient Universal Perception Encoder (EUPE) advances this thread by adding an intermediate proxy-teacher step. The recipe:
- Train a large proxy teacher by distilling from a diverse teacher pool: DINOv2 and DINOv3 (self-supervised dense features), the SAM family (SAM, SAM 2, SAM 3) for segmentation, and CLIP / SigLIP / SigLIP-SO400M for vision-language alignment.
- Distill the proxy teacher down into a compact student under 100M parameters.
The intermediate step matters because direct multi-teacher distillation into a small student loses signal: the teachers disagree at the feature level and the student capacity cannot represent the union. A single proxy resolves the disagreements first, then transfers a coherent feature space.
The released family includes ViT-T/S/B and ConvNeXt T/S/B variants, all under 100M parameters, with weights on Hugging Face. Evaluation spans image classification (ImageNet, ObjectNet, SUN397, iNaturalist), dense prediction (ADE20K and COCO segmentation, NYU and KITTI depth, SPair matching), and vision-language tasks (VQA, image-text retrieval). EUPE matches or exceeds same-size domain experts across these domains. For video systems, which are particularly sensitive to per-frame inference cost, a single backbone covering classification, dense prediction, and VLM front-end means fewer encoders to load and amortize, and the latency win compounds with every frame in the stream.
Efficient Attention for Long Sequences
Once frames are encoded, attention becomes the bottleneck. Standard self-attention is O(n²) in sequence length, which is unaffordable for long video. Three families of remedies have stabilized.
Sliding-window and sparse attention. LongLLaMA, Mistral’s sliding-window, and DeepSeek’s Native Sparse Attention. Each restricts attention to a local or learned subset of tokens.
Linear attention. Performer, Linformer, and Nyströmformer (Xiong et al., AAAI 2021), which uses Nyström-based low-rank approximation of the softmax kernel to achieve linear complexity. Recent production systems extend this thread: Qwen3-Next pairs Gated DeltaNet (a linear-attention variant) with full attention in a 3:1 ratio. These approaches help when sequence length dominates compute.
Hybrid architectures. Mamba-Transformer hybrids (Jamba, Nvidia Nemotron Nano 2) keep self-attention for short-range relationships and use SSM blocks for long-range dependencies. For video this maps naturally: most spatial reasoning is local, while temporal reasoning extends across many frames.
The structural pattern that holds for video is factorized spatial-temporal attention. Spatial attention within a frame is O(P²) where P is patches per frame and small; temporal attention across frames is O(T²) where T is frame count and can be large. Full attention on the spatial axis combined with linear or sparse attention on the temporal axis works well for most workloads, and recent open-weight video VLMs (Qwen3-VL, LLaVA-Video) converge here.
Segmentation and Tracking on Device
Once you can encode and attend efficiently, the next question is what to extract from each frame, and segmentation and tracking are the workhorse primitives.
SAM (Kirillov et al., Meta, ICCV 2023) defined the prompt-driven segmentation foundation model, and SAM 2 (Ravi et al., Meta, 2024) extended it to video with a memory module that maintains separate FIFO queues for recent and prompted frames, plus object pointers, with temporal positional embeddings on the recent queue only. Several parallel lines take different architectural paths: XMem (Cheng et al., ECCV 2022) introduced the multi-store memory architecture (sensory, working, long-term) that informed many later designs; DEVA (Cheng et al., ICCV 2023) decouples task-specific image-level segmentation from a universal temporal propagation module trained once and reused across tasks; and Cutie (Cheng et al., CVPR 2024 Highlight) reads object-level memory through a query-based object transformer rather than propagating pixel-level features. SAM 2 and its compressed descendants dominate the foundation-model production stack today, while Cutie, DEVA, and XMem hold advantages in long-persistence, decoupled-task, and tight-memory regimes respectively.
Most of our work here has been on compression. EfficientSAM (CVPR 2024 Highlight) introduced SAMI, a masked image pretraining recipe that distills SAM’s image encoder into much smaller backbones; the released ViT-T and ViT-S variants reach within a few mIoU points of the full SAM ViT-H at a fraction of the cost, and the open-source release made on-device segmentation practical for the first time. Efficient Track Anything (ICCV 2025) extended this to video with two changes: a plain non-hierarchical ViT replaces SAM 2’s hierarchical encoder, and an efficient memory module reduces the cost of frame feature extraction and memory computation within SAM 2’s bounded memory bank, yielding roughly 2x speedup on A100 with 2.4x parameter reduction at performance comparable to SAM 2, and ~10 FPS on iPhone 15 Pro Max. EdgeTAM (CVPR 2025) pushed further onto consumer silicon with a 2D Spatial Perceiver that compresses per-frame memory aggressively while preserving the spatial structure needed for accurate tracking, hitting J&F scores of 87.7 / 70.0 / 72.3 / 71.7 on DAVIS 2017, MOSE, SA-V validation, and SA-V test while running at 16 FPS on iPhone 15 Pro Max. That is the first time foundation-model-grade video tracking has been deployable on a consumer mobile device.
Most per-frame computation is redundant across adjacent frames, so memory-efficient propagation drives the production gains, not raw model size.
3D and Depth from Video
Segmentation and tracking handle 2D structure, but video also carries strong cues for 3D through parallax, motion, and temporal consistency. The methods that have stabilized are still predominantly image-based, applied per-frame or fed into multi-view reconstructors that treat sampled frames as views; truly temporal-video-native depth is an active but immature area. Extracting metric depth used to require specialized architectures.
DepthLM (ICLR 2026 Oral) shows that a vision-language model with a 3B-parameter backbone, trained with standard text-based supervised fine-tuning and no architecture change, can match or beat dedicated specialists like DepthPro and Metric3Dv2 on metric depth benchmarks. The recipe has three pieces: visual prompting that renders markers on images rather than using text coordinate prompts; intrinsic-conditioned augmentation that unifies focal length to resolve camera ambiguity during training; and supervised fine-tuning on sparsely labeled images, with just one labeled pixel per training image.
DepthLM is the VLM-based entry in a four-way race for metric depth. The dedicated specialists, DepthAnything (Yang et al., CVPR 2024) trained on 1.5M labeled and 62M+ unlabeled images and DepthAnything V2 (NeurIPS 2024) trained on ~595K synthetic-labeled and ~62M pseudo-labeled real images, plus DepthPro (Bochkovskii et al., Apple) and Metric3D v2, still set per-task SOTA on most depth benchmarks. The diffusion-prior approach is best represented by Marigold (Ke et al., CVPR 2024 Oral), which fine-tunes a pretrained image diffusion model and gets strong zero-shot generalization at the cost of latency. The reconstruction family, including DUSt3R and MASt3R (Naver Labs Europe) and the more recent VGGT (Visual Geometry Grounded Transformer, Wang et al., Oxford VGG and Meta AI, CVPR 2025 Best Paper), predicts 3D scene structure, camera parameters, and depth jointly from sparse views, which is useful when geometry matters more than per-pixel depth. Specialists win on raw accuracy, reconstruction wins when camera pose is needed, diffusion priors win on out-of-distribution generalization, and VLM-based approaches like DepthLM win when the same model handles depth and higher-level reasoning.
The implication is structural: if 3D understanding rides on the same VLM that handles reasoning, the stack collapses two perception models into one, and for an AR headset or a robot that simplifies deployment substantially.
Long-Form Video Understanding
Spatial primitives describe what is in a single frame. The harder problem is understanding what an entire video means as length grows from seconds to hours.
LongVU (ICML 2025) addresses this with spatiotemporal adaptive compression. The four-stage pipeline:
- Temporal redundancy removal via DINOv2. Sample at 1 FPS, compute DINOv2 features within non-overlapping 8-frame windows, drop frames whose features are highly similar to neighbors. Roughly 45.9% of frames are retained after this stage. DINOv2 is used here because its vision-centric self-supervised features are well-suited to inter-frame similarity pruning, while SigLIP is retained downstream for language-aligned semantics.
- Feature fusion. Extract SigLIP features from the surviving frames and combine them with DINOv2 features through a Spatial Vision Aggregator.
- Cross-modal query selection. Compute attention between frame features and the LLM’s text-query embeddings; retain the top-Nh frames at full 144 tokens and reduce the rest to 64 tokens, balancing detail against budget.
- Spatial Token Compression. In sliding windows of 8 frames, the first frame keeps full token resolution while tokens in subsequent frames whose cosine similarity to the corresponding anchor token exceeds 0.8 are pruned, yielding about 40.4% additional token reduction.
LongVU is built on Qwen2-7B (with a Llama 3.2-3B lightweight variant) and reaches 60.6% on VideoMME and 65.4% on MLVU with 1 FPS adaptive sampling, outperforming uniform-frame baselines like LLaVA-OneVision while using a fraction of the tokens.
Our follow-up Tempo pushes adaptive token allocation further. A small VLM up front acts as a query-aware compressor: it reads the question first, then routes token budget per-segment, swinging from 0.5 to 16 tokens per frame depending on relevance. The compressed representation is handed to a larger LLM for downstream reasoning. At an 8K visual token budget, the 6B Tempo model reaches 52.3 on LVBench (where videos average over an hour), beating both GPT-4o and Gemini 1.5 Pro at that budget.
LongVU and Tempo sit in a broader thread of compression approaches. LLaMA-VID (Li et al., ECCV 2024) takes aggressive context-token compression to an extreme: each frame is reduced to two learned tokens, a context token encoding instruction-guided information and a content token capturing visual cues, which enables very long videos at the cost of some spatial detail. VideoChat-Flash (ICLR 2026) introduces hierarchical clip-to-video token compression (clip-level during encoding, then video-level in the LLM context) inside a multi-stage short-to-long training scheme, achieving roughly 50x compression with minimal performance loss and 99.1% needle-in-a-haystack accuracy on 10K-frame inputs. PLLaVA and successors apply parameter-free pooling at the projection layer. Frontier multimodal models with very long native context windows (Gemini 2/3 with 1M+ tokens, recent Qwen3-VL variants) go the other way: rather than compress aggressively, they push the budget upward and let attention sort out relevance. The tradeoff is concrete: aggressive compression preserves on-device feasibility but can drop information, while large native contexts preserve information but require frontier-tier compute. LongVU sits at the on-device end of the spectrum, Gemini at the frontier end, and different deployment targets pick different points.
Long-form video understanding is dominated by token budget, and the field is converging on some combination of adaptive token allocation, memory mechanisms, and language-guided pruning. The open question is whether these techniques can work in streaming mode, where the model cannot see the whole video upfront, rather than batch; nobody has solved that cleanly.
Audio-Visual Fusion
Beyond length and spatial structure, audio is what disambiguates many videos, especially egocentric and conversational footage, and how a model fuses audio with the visual stream is a separate architectural choice from anything covered above.
Encoder stitching is the historical default: separate audio and visual encoders feed pooled embeddings into a language model. Cheap and modular, but cross-modal alignment is shallow because the encoders never see each other’s data during training. Native multimodal training treats text, image, video, and audio tokens uniformly through a shared backbone. Qwen3-Omni is the strongest open-weight example as of April 2026, with state-of-the-art results on 22 of 36 audio and audio-visual benchmarks (32 of 36 among open-source models) while sharing weights with the visual stack, and Gemini’s native multimodal architecture follows a similar internal pattern.
EgoAVU (CVPR 2026 Highlight) takes a third path. Rather than propose a new fusion architecture, EgoAVU builds the first large-scale egocentric audio-visual benchmark and dataset and evaluates how existing VLMs (Qwen2-VL, Gemini, LLaMA 3) perform when audio embeddings are stitched alongside the visual tokens. Audio in egocentric video carries distinct information from third-person video: ambient sound, hand-object contact noise, the wearer’s own voice, and conversational partners are all anchored on the wearer’s body in ways they are not in YouTube-style footage. The evaluation shows that audio adds substantial signal on egocentric understanding tasks and that stitched audio encoders into existing VLMs are already a strong baseline; the headroom is in better data and training, not in radical architectural changes.
Native multimodal wins at scale, but egocentric data is underrepresented in pretraining corpora and wearables are the deployment target where this distribution dominates. Benchmark-driven progress on the egocentric slice matters more for wearable products than for cloud video generally.
Reasoning Over Video
Encoding, compression, and fusion produce a representation; reasoning is what turns that representation into an answer. A VLM that watches a video and answers in one forward pass often fails on temporally-extended questions, because compressing hours of footage into a fixed-length representation and reading the answer back out drops too much nuance.
VideoAuto-R1 (CVPR 2026) starts from a counterintuitive observation: for RL-trained video VLMs, direct answering often matches or beats chain-of-thought reasoning while costing a lot more tokens. The proposed recipe is “reason-when-necessary.” During training, the model first generates an initial answer, then performs reasoning, then outputs a reviewed final answer; both the initial and reviewed answers are supervised through verifiable rewards. At inference, the confidence of the initial answer determines whether to spend tokens on reasoning at all. The result: state-of-the-art accuracy on video QA and grounding benchmarks while reducing average response length roughly 3.3x (from ~144 to ~44 tokens). Thinking-mode activates rarely on perception-oriented questions and often on reasoning-intensive ones, which suggests that explicit reasoning helps but is not always necessary, and gating it on confidence is a meaningful efficiency win.
Several lines have converged on related patterns. Video-of-Thought (Fei et al., ICML 2024) introduced step-by-step video reasoning that decomposes a complex question from low-level pixel perception to high-level cognitive interpretation, paired with the MotionEpic VLM that grounds reasoning in spatial-temporal scene graphs. VideoTree (Wang et al., CVPR 2025) builds a query-adaptive hierarchical tree by iteratively selecting the keyframes most relevant to the question, achieving strong long-form QA without any training. Plan-and-execute approaches in the broader VLM-agent literature share the same structural pattern with different implementations. Single-pass video VLMs fail predictably on long-horizon questions, and the field has settled on two-stage inference. The remaining question is whether the reasoning step should be explicit (interpretable, easier to debug, slower) or implicit through learned routing (faster, harder to introspect).
Deployment: Where Video Intelligence Actually Runs
Video deployment splits into three tiers, and the choice between them is driven as much by economics, latency, and data residency as by raw model capability.
Cloud. Frontier APIs like Gemini’s video understanding endpoints and the multimodal flagships from OpenAI and Anthropic that accept image and audio (with video typically handled via frame sampling); specialized providers like Twelve Labs (Marengo embeddings and Pegasus video LLM with hour-scale temporal segmentation); hyperscaler services like AWS Rekognition Video, Azure Video Indexer, and Google Video Intelligence. The cloud tier gets you the largest models and the longest context with no client-side complexity, but it pays in round-trip latency (hundreds of milliseconds minimum), cost (10-100x edge inference per task), and bandwidth that breaks for continuous video at scale.
Edge servers. On-prem GPU appliances or smart camera bridges, like Verkada’s bridges, Hayden AI’s on-device units, or industrial-inspection servers running Cosmos NIM. This tier trades the cloud’s latency and data-residency problems for a hardware investment and a fragmented stack across customers, and supports mid-size models in the 3-30B range.
On-device. Mobile SoCs, AR glasses silicon, embedded NPUs. Apple Intelligence on iPhone, Qualcomm Robotics RB5/RB6 in robotics, Qualcomm Snapdragon AR1 in Ray-Ban Meta and Snapdragon XR2 Gen 2 in Quest 3. Zero-latency, fully private, no bandwidth, and it scales with device shipments. The cost is a tight power budget (1-30W), limited memory bandwidth, and a fragmented runtime landscape.
For continuous video the math forces the choice. A body-cam recording 12 hours per shift cannot ship 100GB per day to the cloud per officer, so the fast-thinking layer has to live on the device, with cloud or edge servers used for the deeper queries. Hybrid architectures, not pure cloud or pure on-device, are the production default.
Quantization Recipes for Video Models
Video models inherit the quantization recipes that have stabilized for LLMs and VLMs.
- W4A16 (4-bit weights, 16-bit activations) is the default for VLMs and VLAs at the edge. Recent open releases including the Embedl-quantized Cosmos-Reason2 (2B) variants show the recipe holds across multimodal architectures with minimal accuracy loss.
- NVFP4 (4-bit weights and 4-bit activations in NVIDIA’s FP4 format with per-block-of-16 FP scales) unlocks Blackwell-tier hardware (Jetson AGX Thor) and is the production-grade upgrade where supported.
- W8A8 remains the safer fallback for mature vision and segmentation models.
- Sub-4-bit quantization (W2A16, ternary, mixed precision) continues to improve. Our ParetoQ (NeurIPS 2025) work mapped the full quantization Pareto frontier and showed that at 2 bits and below, models learn fundamentally different representations than at 3-4 bits; for a fixed memory budget, a larger 2-bit model can beat a smaller 4-bit model. That shifts the design space for very-low-power video deployment, though it still requires QAT and is not yet standard for production VLMs.
- KV cache quantization matters more for video than for text. The KV cache for a long video can dominate memory, and rotation-based methods like SpinQuant (which jointly quantize weights, activations, and KV cache) have been particularly effective at compressing it to 3-4 bits per element.
Runtime Stack
For PyTorch-based deployment, ExecuTorch (Meta) is the natural path. ExecuTorch reached 1.0 GA in October 2025 and now powers Meta’s on-device AI across Instagram, WhatsApp, Messenger, Facebook, Quest 3, and Ray-Ban Meta, with backends spanning Apple Core ML, Qualcomm QNN, Arm, MediaTek NeuroPilot, and Vulkan. For video pipelines, ExecuTorch’s support for streaming inference and selective recomputation matters because re-encoding every frame from scratch is wasteful. Other paths cover other ecosystems: Apple Core ML for Apple platforms, LiteRT-LM plus Qualcomm QNN for Android, Nvidia Isaac plus NIM on Jetson, Intel OpenVINO for x86 industrial. No single runtime wins, and production video systems usually ship the same model compiled for several backends.
What’s Still Hard
Several problems remain open across the stack.
Continuous-stream understanding at hour-plus durations. LongVU and similar techniques assume batch mode where the whole video is available. Streaming mode, where the model has to maintain understanding while video keeps arriving, is much harder. Memory mechanisms, retrieval-augmented architectures, and incremental token compression are all in progress; none are solved cleanly.
Sparse-event detection. Most production video is uninteresting. Finding the three frames out of 86,400 that matter, without paying for full inference on all 86,400, requires hierarchical attention or learned selection. Schema-driven extraction over known classes now ships commercially (Twelve Labs’ Pegasus pulls structured metadata against a customer-defined schema); open-set “show me anything anomalous” remains unsolved.
Cross-camera and cross-clip reasoning. A surveillance ops team often wants to ask questions across many cameras and many time windows. Library-scale retrieval over indexed videos ships (Twelve Labs’ Marengo ranks moments across a video library), but that is ANN retrieval over independent embeddings, not joint reasoning. Multi-stream attention, cross-camera identity persistence, and global temporal reasoning are all open.
Real-time sub-watt inference for AR glasses. Today’s mobile NPUs do tens of TOPS in tens of milliwatts, but an AR glass AI assistant needs to do continuous video understanding inside a 1-3W envelope that includes everything else the system runs. EUPE-style universal compact encoders, EdgeTAM-style efficient tracking, and aggressive quantization all help, but the gap to always-on Gemini-grade understanding on glasses is still 5-10x in compute efficiency.
Closed-loop evaluation. Public benchmarks measure accuracy on curated multiple-choice question sets. Production systems care about latency under load, drift under deployment shifts, robustness to camera placement and lighting, and intervention rates. Closed-loop methodology lags benchmark accuracy by a wide margin.
Audio-visual generative consistency. When video models generate or edit content rather than understand it (out of scope for most of this post), keeping audio synchronized with visual events is unsolved, which is why most current text-to-video models ship without working audio.
Cross-modal grounding stability. When a VLM is asked “what is the man in the blue shirt doing?”, the model often fails not on language understanding but on grounding the referent across frames. Timestamp-level grounding ships commercially (Pegasus localizes answers to start/end times); spatial grounding (bounding boxes, referent IDs across cuts) still requires bolting on SAM 2 or Grounding DINO.
Closing
A handful of patterns recur across encoding, perception, compression, fusion, reasoning, and deployment. Compress where redundancy is highest, which for video is almost always the temporal axis. Distill universal encoders from multiple teachers rather than ship a fleet of specialists. Factorize attention along the physical structure of the data: spatial within frames, temporal across frames, cross-modal across modalities. Treat quantization as the default rather than as a late optimization. Gate reasoning on confidence rather than running it on every input.
The encoder, compression, and fusion patterns are now stable; the streaming, sub-watt deployment, and closed-loop evaluation patterns are not. The open problems left in efficient video intelligence are mostly about scaling the stable recipes to streaming inputs, sub-watt power envelopes, and production deployments where evaluation has to track a system rather than a benchmark. The work ahead lives in the deployment stack at least as much as in the model layer.